A unit of work done against the DB in a logical sequence.
It is a logical unit of work that contains one or more SQL statements
All these statements in a transaction either gets
Completed successfully (all the changes made to the database are permanent)
Or if at any point any failure happens it gets rollbacked (all the changes being done are undone.)
Sequence is very important in transaction.
# Transfer 100 from A to B
# Transaction-1(T1)
Read(A)
A:= A-100
Write(A)
# Transaction-2(T2)
Read(B)
Y:= Y+100
Write(B)
ACID Properties
To ensure integrity of the data, we require that the DB system maintain the following properties of the transaction.
Atomicity
All or None
Either the entire transaction takes place at once or doesn’t happen at all
Eg:
Both T1 and T2 should execute completly no partial execution
Abort: If a transaction aborts, changes made to the database are not visible.
Commit: If a transaction commits, changes made are visible.
Consistency
Integrity constraints must be maintained before and after transaction.
DB must be consistent after transaction happens
Eg:
Before T(A + B) == After T(A + B)
The total amount before and after the transaction must be maintained
Isolation
Even though multiple transactions may execute concurrently, the system guarantees that, for every pair of transactions Ti and Tj
It appears to Ti that either Tj finished execution before Ti started
Or Tj started execution after Ti finished.
This property ensures that the execution of transactions concurrently will result in a state that is equivalent to
a state achieved these were executed serially in some order.
Durability
After transaction completes successfully, the changes it has made to the database persist, even if there are system failures
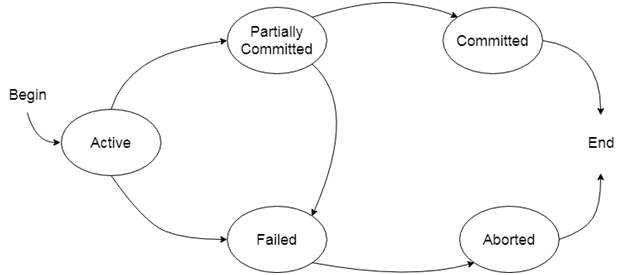
Transaction states
Active state
The very first state of the life cycle of the transaction, all the read and write operations are being performed
If they execute without any error the T comes to Partially committed state
Although if any error occurs then it leads to a Failed state.
Partially committed state
After transaction is executed the changes are saved in the buffer in the main memory.
If the changes made are permanent on the DB then the state will transfer to the committed state and if there is any failure, the T will go to Failed state.
Committed state
When updates are made permanent on the DB.
Then the T is said to be in the committed state.
Rollback can’t be done from the committed states. New consistent state is achieved at this stage.
Failed state
When T is being executed and some failure occurs
Due to this it is impossible to continue the execution of the T.
Aborted state
When T reaches the failed state, all the changes made in the buffer are reversed
After that the T rollback completely. T reaches abort state after rollback. * DB’s state prior to the T is achieved.
After aborting the transaction, the database recovery module will select one of the two operations:
Re-start the transaction
Kill the transaction
Terminated state
A transaction is said to have terminated if has either committed or aborted
How to implement Atomicity and Durability in Transactions
Recovery Mechanism Component of DBMS supports atomicity and durability.
Shadow-copy scheme
Based on making copies of DB (aka, shadow copies).
Assumption only one Transaction (T) is active at a time.
A pointer called db-pointer is maintained on the disk; which at any instant points to current copy of DB.
T, that wants to update DB first creates a complete copy of DB.
All further updates are done on new DB copy leaving the original copy (shadow copy) untouched.
If at any point the T has to be aborted the system deletes the new copy. And the old copy is not affected.
If T success, it is committed as,
OS makes sure all the pages of the new copy of DB written on the disk.
DB system updates the db-pointer to point to the new copy of DB.
New copy is now the current copy of DB.
The old copy is deleted.
The T is said to have been COMMITTED at the point where the updated db-pointer is written to disk.
Atomicity
If T fails at any time before db-pointer is updated, the old content of DB are not affected.
T abort can be done by just deleting the new copy of DB.
Hence, either all updates are reflected or none.
Durability
Suppose, system fails are any time before the updated db-pointer is written to disk.
When the system restarts, it will read db-pointer & will thus, see the original content of DB and none of the effects of T will be visible.
T is assumed to be successful only when db-pointer is updated.
If system fails after db-pointer has been updated. Before that all the pages of the new copy were written to disk. Hence, when system restarts, it will read new DB copy.
The implementation is dependent on write to the db-pointer being atomic
Luckily, disk system provide atomic updates to entire block or at least a disk sector.
So, we make sure db-pointer lies entirely in a single sector.
By storing db-pointer at the beginning of a block.
Inefficient, as entire DB is copied for every Transaction
Log-based recovery methods
The log is a sequence of records.
Log of each transaction is maintained in some stable storage so that if any failure occurs, then it can be recovered from there.
If any operation is performed on the database, then it will be recorded in the log.
But the process of storing the logs should be done before the actual transaction is applied in the database.
Stable storage is a classification of computer data storage technology that guarantees atomicity for any given write operation and allows software to be written that is robust against some hardware and power failures.
Deferred DB Modifications
Ensuring atomicity by recording all the DB modifications in the log but deferring the execution of all the write operations until the final action of the T has been executed.
Log information is used to execute deferred writes when T is completed.
If system crashed before the T completes, or if T is aborted, the information in the logs are ignored.
If T completes, the records associated to it in the log file are used in executing the deferred writes.
If failure occur while this updating is taking place, we preform redo.
Immediate DB Modifications
DB modifications to be output to the DB while the T is still in active state.
DB modifications written by active T are called uncommitted modifications.
In the event of crash or T failure, system uses old value field of the log records to restore modified values.
Update takes place only after log records in a stable storage.
Failure handling
System failure before T completes, or if T aborted, then old value field is used to undo the T.
If T completes and system crashes, then new value field is used to redo T having commit logs in the logs.
Indexing in DBMS
Indexing is used to optimise the performance of a database by minimising the number of disk accesses required when a query is processed.
The index is a type of data structure.
It is used to locate and access the data in a database table quickly.
Speeds up operation with read operations like SELECT queries, WHERE clause etc.
Search Key: Contains copy of primary key or candidate key of the table or something else.
Data Reference: Pointer holding the address of disk block where the value of the corresponding key is stored.
Indexing is optional, but increases access speed. It is not the primary mean to access the tuple, it is the secondary mean.
Index file is always sorted.
Indexing Methods
Primary Index (Clustering Index)
Secondary Index (Non-Clustering Index)
Primary Index (Clustering Index)
A file may have several indices, on different search keys. If the data file containing the records is sequentially ordered, a
Primary index is an index whose search key also defines the sequential order of the file.
NOTE: The term primary index is sometimes used to mean an index on a primary key. However, such usage is nonstandard and should be avoided.
All files are ordered sequentially on some search key. It could be Primary Key or non-primary key.
Dense Index
The dense index contains an index record for every search key value in the data file.
The index record contains the search-key value and a pointer to the first data record with that search-key value.
The rest of the records with the same search-key value would be stored sequentially after the first record.
It needs more space to store index record itself.
The index records have the search key and a pointer to the actual record on the disk.
Sparse Index
An index record appears for only some of the search-key values.
Sparse Index helps you to resolve the issues of dense Indexing in DBMS.
In this method of indexing technique, a range of index columns stores the same data block address, and when data needs to be retrieved, the block address will be fetched.
Primary Indexing can be based on Data file is sorted w.r.t Primary Key attribute or non-key attributes.
Based on Key attribute
Data file is sorted w.r.t primary key attribute
PK will be used as search-key in Index.
Sparse Index will be formed i.e., no. of entries in the index file = no. of blocks in datafile.
Based on Non-Key attribute
Data file is sorted w.r.t non-key attribute
No. Of entries in the index = unique non-key attribute value in the data file.
This is dense index as, all the unique values have an entry in the index file.
E.g., Let’s assume that a company recruited many employees in various departments.
In this case, clustering indexing in DBMS should be created for all employees who belong to the same dept.
Multi-level Index
Index with two or more levels
If the single level index become enough large that the binary search it self would take much time, we can break down indexing into multiple levels.
Secondary Index (Non-Clustering Index)
Datafile is unsorted. Hence, Primary Indexing is not possible.
Can be done on key or non-key attribute.
Called secondary indexing because normally one indexing is already
applied.
No. Of entries in the index file = no. of records in the data file.
It’s an example of Dense index
Types of Databases
Relational Databases
Based on Relational Model.
Relational databases are quite popular, even though it was a system designed in the 1970s.
Also known as relational database management systems (RDBMS), relational databases commonly use Structured Query Language (SQL) for operations such as creating, reading, updating, and deleting data.
Relational databases store information in discrete tables, which can be JOINed together by fields known as foreign keys.
For example, you might have a User table which contains information about all your users, and join it to a Purchases table, which contains information about all the purchases they’ve made.
MySQL, Microsoft SQL Server, and Oracle are types of relational databases.
They are ubiquitous, having acquired a steady user base since the 1970s
They are highly optimised for working with structured data.
They provide a stronger guarantee of data normalisation
They use a well-known querying language through SQL
Scalability issues (Horizontal Scaling).
Data become huge, system become more complex
Object Oriented Databases
The object-oriented data model, is based on the object-oriented-programming paradigm, which is now in wide use.
Inheritance, object-identity, and encapsulation (information hiding), with methods to provide an interface to objects, are among the key concepts of object-oriented programming that have found applications in data modelling
The object-oriented data model also supports a rich type system, including structured and collection types.
While inheritance and, to some extent, complex types are also present in the E-R model, encapsulation and object-identity distinguish the object-oriented data model from the E-R model.
Sometimes the database can be very complex, having multiple relations. So, maintaining a relationship between them can be
tedious at times.
In Object-oriented databases data is treated as an object.
All bits of information come in one instantly available object package instead of multiple tables.
Advantages
Data storage and retrieval is easy and quick.
Can handle complex data relations and more variety of data types that standard relational databases.
Relatively friendly to model the advance real world problems
Works with functionality of OOPs and Object Oriented languages.
Disadvantages
High complexity causes performance issues like read, write, update and delete operations are slowed down.
Not much of a community support as isn’t widely adopted as relational databases.
Does not support views like relational databases.
E.g. ObjectDB, GemStone etc.
NoSQL Databases
NoSQL databases (aka “not only SQL”) are non-tabular databases and store data differently than relational tables.
NoSQL databases come in a variety of types based on their data model.
The main types are document, key-value, wide-column, and
graph.
They provide flexible schemas and scale easily with large amounts of data and high user loads.
They are schema free
Data structures used are not tabular, they are more flexible, has the ability to adjust dynamically.
Can handle huge amount of data (big data).
Most of the NoSQL are open sources and has the `capability of horizontal scaling
It just stores data in some format other than relational.
Hierarchical Databases
As the name suggests, the hierarchical database model is most appropriate for use cases in which the main focus of information gathering is based on a concrete hierarchy, such as several individual employees reporting to a single department at a company.
The schema for hierarchical databases is defined by its tree-like organisation, in which there is typically a root “parent” directory of data stored as records that links to various other subdirectory branches, and each subdirectory branch, or child record, may link to various other subdirectory branches.
The hierarchical database structure dictates that, while a parent record can have several child records, each child record can only have one parent record. Data within records is stored in the form of fields, and each field can only contain one value. Retrieving hierarchical data from a hierarchical database architecture requires traversing the entire tree, starting at the root node.
Since the disk storage system is also inherently a hierarchical structure, these models can also be used as physical models.
Advantage
Hierarchical database is ease of use.
The one-to-many organisation of data makes traversing the database simple and fast, which is ideal for use cases such as website drop-down menus or computer folders in systems like Microsoft Windows OS.
Due to the separation of the tables from physical storage structures, information can easily be added or deleted without affecting the entirety of the database.
And most major programming languages offer functionality for reading tree structure databases.
Disadvantage
Hierarchical databases is inflexible nature
The one-to-many structure is not ideal for complex structures as it cannot describe relationships in which each child node has multiple parents nodes
Also the tree-like organisation of data requires top-to-bottom sequential searching, which is time consuming, and requires repetitive storage of data in multiple different entities, which can be redundant.
E.g., IBM IMS
Network Databases
Extension of Hierarchical databases
The child records are given the freedom to associate with multiple parent records.
Organised in a Graph structure
Can handle complex relations.
Maintenance is tedious.
M:N links may cause slow retrieval.
Not much web community support.
E.g., Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE etc.