# Topic covered
* Scalability
* Horizontal, Vertical Scaling
* Load Balancers
* Caching
* Asynchronism
* Message/Task Queues
* Producer consumer model
* Message Broker
* Publisher subscribe model
1. Scalability
https://www.rootstrap.com/blog/horizontal-vs-vertical-scaling/
Scalability refers to the ability of a system to handle an increasing workload, both in terms of data volume and user requests,
without compromising its performance.
It is a crucial aspect of designing any modern software system, as the demands placed upon it can grow exponentially over time.
To achieve scalability in system design, there are two common methods:
Verticalscaling (scaling up)Horizontalscaling (scaling out)

2. Vertical scaling (aka scaling up)
Vertical scaling is the ability to increase the capacity of single machine by increasing the resource.
This is the traditional method of scaling .
Adding power to your existing machine means you have one server, and you add more RAM and CPU resources
# Upgrading -
* EC2 instance from `t2.nano to t2.micro/t2.small`
* Storage `HDD to SDD`
Pros
- Easy Implementation
- Less technical knowledge required
- Lower server costs
Cons
Manual upgrades(downtime)- Not flexible –>
Scale up and scale down not possibleaccording to server demands. Single point of failureand required downtime to make changes
3. Horizontal scaling (aka scaling out)
This method involves adding new machines to handle increased system requests.
Multiple devices are connected to distribute the workload and improve system resilience.
Horizontal scaling is generally less expensive than vertical scaling and offers better fault tolerance and increased capacity.
To connect two or more machines we need another node call Load Balancer
Pros
Automated server increaseto match usageLow downtime, no downtime needed for server upgrades
Cons
- Architectural design is
highly complicated - Cost may be higher
Data consistencycan be challenging across multiple machines
# Following technique are used for horizontal-scaling
* Load balancing
* Database replication
* Database partitioning
4. Load balancing
Load balancing is a critical concept in system design that ensures efficient distribution of incoming network traffic
across multiple servers or resources.
It helps achieve scalability, enhance system performance, and ensure high availability.
A load balancer works as a traffic cop sitting in front of your server and routing client requests across all servers.
It distributes the set of requested operations (database write requests, cache queries) effectively across multiple servers
and ensures that no single server bears too many requests that lead to degrading the overall performance of the application.
- Example: Load Balancers -
- Software:
AWS ELB, HAProxy, LVS … - Hardware: Barracuda,
Cisco, Citrix, F5 …
- Software:

Load Balancing- Routing Algorithms
Round-robin: Requests are distributed to application servers in rotation.
Weighted Round-robin: Builds on the simple Round-robin technique to account for differing server characteristics such as compute and traffic handling capacity using weights that can be assigned via DNS records by the administrator.
Least Connections: A new request is sent to the server with the fewest current connections to clients.
The relative computing capacity of each server is factored into determining which one has the least connections.
Least Response Time: Sends requests to the server selected by a formula that combines the fastest response time and fewest active connections.
Least Bandwidth: This method measures traffic in megabits per second (Mbps), sending client requests to the server with the least Mbps of traffic.
Hashing: Distributes requests based on a key we define, such as the client IP address or the request URL.
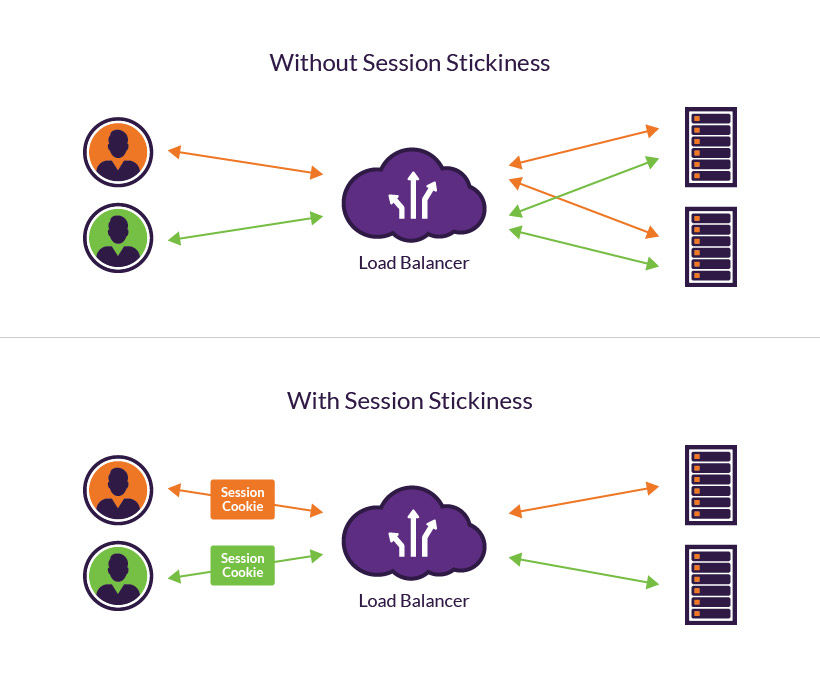
Sticky Session
https://www.imperva.com/learn/availability/sticky-session-persistence-and-cookies/
Session stickiness (aka session persistence) is a process in which a load balancer creates an affinity between a client and a specific network.
The load balancer can start routing all of the requests of this user to a specific server
i.e. the user should land on the same server on his every request
# Can be archived by
* Load balancer should remember on which server client is linked
* Client can remember Server_ID using cookie
5. Caching
Caching is a system design concept that involves storing frequently accessed data in a location that is easily and quickly accessible.
The purpose of caching is to improve the performance and efficiency of a system by reducing the amount of time it takes to access frequently accessed data.
Caching can be used in a variety of different systems, including web applications, databases, and operating systems.
Cache in Computer - L1, L2, L3
- L1 - smallest and fastest - integrated in CPU
- L2 - larger and slower than L1 - it is located farther away from the cores
- L3 - larger and slower than L2 - shared between all cores.
Examples
Here are some commonly used technologies for caching
Redis
Memcached
Amazon Elasticache
Aerospike
Use cases
Caching can have many real-world use cases such as
Database Caching
Content Delivery Network (CDN)
Domain Name System (DNS) Caching
API Caching
Cache Invalidation - When to update the cache
Cache invalidation is a process where the computer system declares the cache entries as invalid and removes or replaces them.
If the data is modified, it should be invalidated in the cache, if not, this can cause inconsistent application behavior.
https://github.com/karanpratapsingh/system-design#caching
https://github.com/donnemartin/system-design-primer#cache
Cache-aside
Cache don’t talk directly to DB, Server talks to db and update the cache.
Data can become stale if TTL(cache expiry) is high.
Memcached is generally used in this manner.

* Look for entry in cache, resulting in a cache miss
* Load entry from the database
* Add entry to cache
* Return entry
- Read through cache pattern/strategy
- Server talks to cache and cache directly talks to DB
Write through cache
Data is written into the cache and the corresponding database simultaneously.
Application adds/updates entry in cache
Cache synchronously writes entry to data store
Return
 Pro: Fast retrieval, complete
Pro: Fast retrieval, complete data consistency between cache and storage.
Con: Higher latency for write operations.
Write around cache
Where write directly goes to the database or permanent storage, bypassing the cache.

Pro: This may reduce latency.
Con: It increases cache misses because the cache system has to read the information from the database in case of a cache miss.
As a result, this can lead to higher read latency in the case of applications that write and re-read the information quickly.
Read happen from slower back-end storage and experiences higher latency.
Write-behind (write-back)
Where the write is only done to the caching layer and the write is confirmed as soon as the write to the cache completes. The cache then asynchronously syncs this write to the database.
Add/update entry in cache
Asynchronously write entry to the data store, improving write performance

Cache Eviction policies
Following are some of the most common cache eviction policies:
First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
Least Recently Used (LRU): Discards the least recently used items first.
Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
6. Asynchronism
Synchronous means to be in a sequence, that is every statement of the code gets executed one by one.
Therefore, a statement has to wait for the earlier statement to get executed.
Eg: Phone Call, Line-by-line execution of python code.
Asynchronous process allows to execute further statement immediately without blocking them before the execution of current statement.
Eg: Email, Line-by-line execution of JS code with setTimeout(), async()
Asynchronous workflows help
reduce request timesby asynchronously execute expensive operations outside the HTTP request-response cycle.- Also help by
doing time-consuming work in advance, such as periodic aggregation of data.
In Microservices architecture asynchronism can be achieved by - message queue, message broker
Message/Task Queues
https://medium.com/must-know-computer-science/system-design-message-queues-245612428a22
A Message Queue provides an asynchronous communications protocol, which is a system that puts a message onto a Message Queue
and does not require an immediate response to continuing processing.
A message queue is a data structure that facilitates communication between applications by sending, receiving,
and storing messages using the queue data structure.
It enables different parts of a system to communicate and process operations asynchronously.
It is limited to allowing communication between two applications only, i.e. each message is processed only once, by a single consumer.
For example: MSMQ, Amazon SQS stores the message in the queue until it is processed by the first consumer, after which it will automatically remove it from the queue.
.
Producer consumer model
One to One - One message can be consumer by only one customer
It is a point-to-point messaging model where producers knows about consumer beforehand and only the specified consumer can consume the message from the queue
- Types based on ordering
Orders MQs- FIFO - Eg: Text message *Unordered MQs- Eg: Invoice generation
Message Broker
A message broker is a separate component that manages queues.
It is an extension to the message queue and provides a mechanism of publisher-subscriber relations.
It allows multiple services to communicate with each other by translating and transporting messages to the appropriate service
Example: RabbitMQ, Kafka, ActiveMQ
.
Publisher subscribe model
One to Many - One message can be consumer by any number customer
It is a broadcast messaging model where the producer (also called publisher) has no knowledge of the consumer
(also called receiver) and it just publishes a message in the queue by specifying a class or tag.
Any component (receiver) which has subscribed to that class or tag will receive the message.