1.1 Data Science
Data science is the domain of study that deals with vast volumes of data using modern tools and techniques
to find unseen patterns, derive meaningful information, and make business decisions.
Data science uses complex machine learning algorithms to build predictive models.
Data Science is a field which incorporates Artificial Intelligence, Data Mining, Big Data, Machine Learning, and Deep Learning.
1.2 Why Data Science
- Give you decision making power
- One of the most in-demand skills sought by major tech companies globally
- Provide ample freelancing opportunities
- Job stability for the years to come as AI is being adopted in all major domains.
1.3 AI vs ML vs DL
- Artificial Intelligence(AI)
- Smart applications that can perform its own task without any human intervention
- Eg: Self Driving Car, Robots
- Machine Learning(ML)
- It provides
stats toolsto learn, analyze, visualize and develop predictive models from the data. - Eg: Recommendation System
- It provides
- Deep Learning(DL)
- Mimic humab being - Multi layered Neural network
- Eg: Object detection, Image Recogination, ChatBot

1.4 Machine Learning
Machine Learning is said as a subset of artificial intelligence that is mainly concerned with the development of algorithms which allow a computer to learn from the data and past experiences on their own.
Classification of Machine Learning
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
1.4.1 Supervised Learning
Supervised learning is a type of machine learning method in which we provide sample labeled data to the machine learning system in order to train it, and on that basis, it predicts the output.
Traing data is both input + output, and based on training it will predict output of new inputs.
- Types
- Classification
- Regression
Classification
It is used to identify the category of new observations on the basis of training data.
i.e based on the input, the categorical outputs is predicted
Eg: Email Spam Detector
Regression
Regression is used to predict the continuous/real output based on the input and output training data.
It predicts continuous/real values such as temperature, age, salary, price, etc.
Eg: Advertisement and sales
1.4.2 Unsupervised Learning
Traing data is only input, and based on training it will create clusters
- Types
- Clustering
- Association
1.4.3 Semi-Supervised Learning
Combination of Supervised + Unsupervised Learning
The cost to label the data is quite expensive as it requires the knowledge of skilled human experts. The input data is combination of both labeled and unlabelled data.
1.4.4 Reinforcement Learning
Reinforcement Learning is an area of ML concerned with how intelligent agents ought to take actions in an environment in order to maximize the notation of cumulative reward.
The reinforcement learning process is similar to a human being; for example, a child learns various things by experiences in his day-to-day life.
- Types
- Positive Reinforcement Learning
- Negative Reinforcement Learning
1.5 Dataset
The dataset is divided into different types before training or doing any predicting
- Training Dataset
- Train the model
- Validation Dataset
- Hyper parameter tuining of the model
- Test Dataset
- Test the model accuracy
Eg:
- TD: Books - Learn Q&A - Train
- VD: Different Book - Learn Q&A - Train
- TD: Exam Paper
1.6 Errors in Machine Learning
- Reducible errors
- These errors
can be reducedto improve the model accuracy. - Types -
BiasandVariance
- These errors
- Irreducible errors
- These errors will
always be presentin the model
- These errors will
Bias
Bias tells about the accuracy of training-dataset
- Low Bias - High Accuracy
- High Bias - Low Accuracy
Variance
Variance tells about the accuracy of test-dataset
- Low Variance - High Accuracy
- High Variance - Low Accuracy
1.7 Overfitting and Underfitting
- Overfitting - - >
Low Bias and High Variance- For training dataset - accuracy is high
- But for new/test dataset - accuracy is low
- Underfitting - - >
High Bias and High Variance- For training dataset - accuracy is low
- Also for new/test dataset - accuracy is low

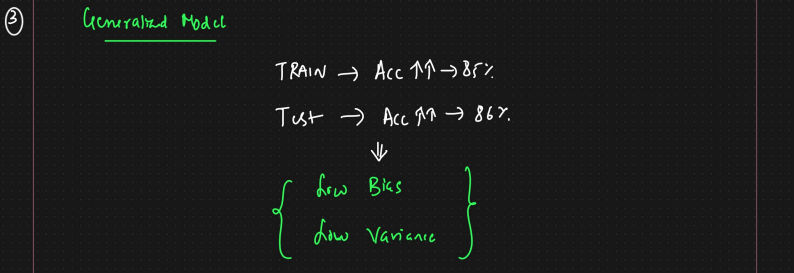
- Generalized Model - - >
Low Bias and Low Variance- For both training and test dataset - accuracy is high
Model should be of this type